Training
The Training section is where you fine-tune your AI assistant using the data prepared in the Data Pre-Processing phase. This process customizes the assistant to better understand your application's context, structure, and user queries.
Training involves providing a dataset of Questions and Answers (Q&As) and augmenting it with additional variations to enhance the model’s understanding.
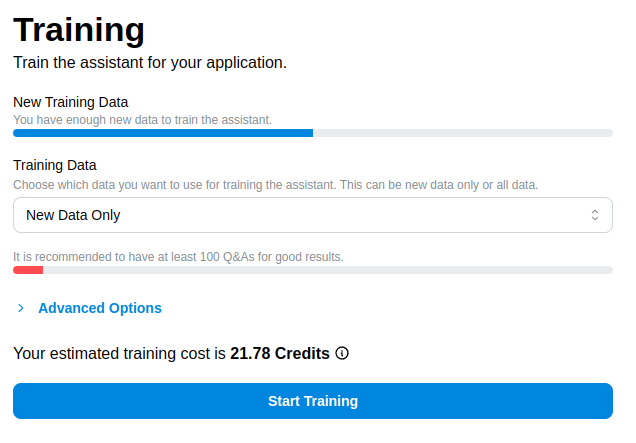
Training Form Overview
The training form provides options for configuring and initiating the training process. Below are the key fields and their purposes:
New Training Data Progress Bar
- Indicates whether there are enough new (unfrozen) Q&As available for training the assistant.
- Ensure that you have sufficient new data to meet the required minimum.
Training Data
- Options:
- New Data Only: Uses only new (unfrozen) Q&As for training.
- All Data: Includes both new (unfrozen) and previously frozen Q&As in the training dataset.
Progress Bar
- Displays the sufficiency of the selected dataset to meet the recommended minimum for fine-tuning.
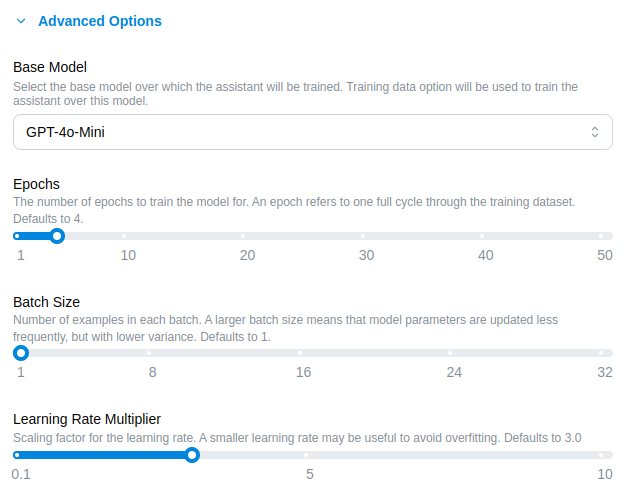
Advanced Options
Click the Advanced Options dropdown to customize the training process further:
-
Base Model: Select the base model for training. By default, the last trained model is used. If you want to train from scratch, you can choose "GPT-4o-mini".
-
Epochs: Specify the number of epochs (training cycles). Recommended default is 3.
-
Batch Size: The number of examples processed in each batch. Recommended default is 1.
-
Learning Rate Multiplier: A scaling factor for the learning rate, which influences how the model updates during training. Recommended default is 3.0.
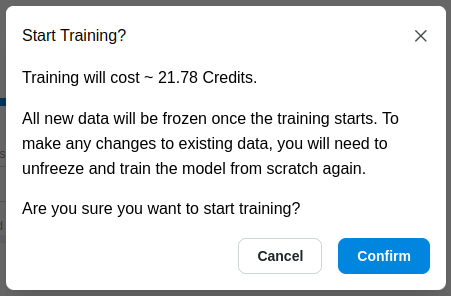
Estimated Training Cost
- Training costs are displayed in credits and depend on the volume of data augmented for training.
- Actual costs may vary up to 2x the estimate due to the additional augmented data generated by the system. However, the actual cost is typically close to or less than the estimate.
Start Training
Submitting Training
-
Once you’ve configured the form, click the Start Training button.
-
A confirmation modal will appear, summarizing the selected options. Confirm to proceed.
What Happens During Training?
-
Freezing Knowledge:
- Once training begins, all Q&As used in the process are frozen to prevent edits.
- This ensures consistency in training and avoids conflicts caused by training with different answers for the same question.
- Frozen knowledge can be unfrozen at any time in the Data Pre-Processing section.
-
Queueing Data for Training:
- The selected dataset is augmented with AI to generate variations of questions and answers.
- Augmented data and user-provided data are split into training and validation sets.
- The prepared data is uploaded for fine-tuning the assistant.
Training Timeline
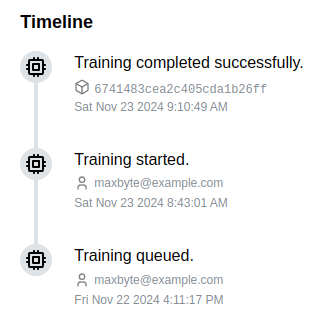
The Training Timeline panel on the right provides a live update on the training progress:
- Queued: Training data is waiting to be processed.
- Training: The model is currently being fine-tuned.
- Completed: Training is finished, and the model is ready for use.
Once the training reaches the Completed state:
- The Model ID is displayed and can be copied for reference.
- Credits are deducted from the organization’s credit balance based on the final training cost.
Here’s the revised section with your updates. It includes the ability to enable RAG at any time, Q&A indexing, and cites industry sources for RAG benefits:
Enabling RAG for a Project Version
To improve your assistant’s accuracy, you can now enable Retrieval-Augmented Generation (RAG) at any point in your project version lifecycle—even after you've already fine-tuned a model.
How to Enable or Activate RAG
Below the Start Training button, there’s now a switch for:
Enable indexing for RAG grounded responses

Toggle it on to activate semantic indexing of your Q&A knowledge. Once training or re-training completes, your assistant will start grounding its responses in your indexed knowledge base.
After activation, you’ll see:
✅ RAG is enabled for this version.

Important Constraints
-
🔐 Deployment control: Even after RAG is enabled for a project version, it must be explicitly turned on for each API key deployment. You can do this either:
- During API key creation, by checking the “Enable RAG” option
- Or later, through the API key settings
This ensures you have full control over when and where RAG is used during inference.
-
🔄 Enable any time—even after initial training of a version.
-
⚠️ Non-reversible: once enabled for a version, RAG cannot be turned off for that version.
-
🆕 Disabled by default: new versions don’t include RAG unless manually enabled.
-
💸 Training is no additional cost, but RAG incurs a separate runtime usage charge, typically 2× that of a fine-tuned model. See our Pricing page for details.
📚 Why It Works: Q&A Indexing vs Document Indexing
Unlike generic document indexing, Navigable now indexes your Knowledge Q & A pairs—structured “Question → Answer” entries from your content. This results in:
- Better recall and semantic matching
- Higher retrieval relevance for user inquiries
- Improved accuracy, over raw document chunking
By indexing Q&As directly, our search retrieves answers more precisely—leading to better model grounding.
🎯 Why Enable RAG?
RAG dramatically boosts accuracy by grounding LLM responses in your knowledge base:
- 📈 Consistent >90% accuracy in all tested scenarios
- Fine-tuned models alone delivered 70–85%, combined with our RAG approach, reached 90–99% rates
- Industry-wide, RAG reduces hallucinations by 20‑30%
The Benefits of RAG (Industry Insights)
Implementing RAG structures powerful advantages:
- Reduces hallucinations by grounding in actual indexed content
- Keeps knowledge fresh and dynamically updated without retraining
- Allows domain-specific Q&A precision—no need to fine‑tune for every new dataset
- Increases transparency and trust by enabling traceable, source-based answers
Best Practices for Training
- Sufficient Data: Ensure you have enough Q&As to meet the recommended minimum.
Next Steps
After training is queued, you can skip to the Evaluation section to manage test cases to evaluate your assistant's responses.